
In a library that bends dimensions to fit its needs, space ceases to be an issue. Nevertheless, the vastness of the Archive’s census data is overwhelming. After days of cataloging, you have barely touched any of the records for even a single reality, all of which are contained in a single alcove of one fractal tower. You are aware of at least three such towers, but suspect there are many more — when you asked the Archivist, they laughed manically for a full minute before rebuking your attempt to apply numbers and logic to a collection of data items.
This post is a little different from normal, at least insofar as normality has been established by the previous two posts. There will be no insightful comments today. Instead, we are going to build the foundations on which many future posts will depend: Data & Dragons.
These foundations will be built on observation. By studying how players make characters, we can identify the features that are considered interesting or valuable, and those that are not. Once we have these features of interest, we can analyse whether there are common trends.
As an example, consider class and subclass. If all Fighters pick the same subclass, this would suggest it offers a clear advantage over the others. We could then compare subclasses to identify the problem, and address it. If the subclass is too complicated to be usable, we could simplify it. If it is mechanically weaker, we could strengthen it. Examining data can inform the decisions we make, and help us create better rules in the future.
This article comes a little closer to scientific vigor than most of my writing. Please do not let that put you off — the conclusions it leads us will make it worth our time. If statistics and data processing is not for you, you can take the existence of this article as proof I have thought this through, and can check the comments for any objections to my reasoning.
Data
First, we need data. In this era, that is not hard. This dataset has been made publicly available on Github by Ogan Mancarci. The dataset contains details of a large number of characters added through an online portal. As with any approach, this method is imperfect. This article will address the strengths and weaknesses of the method, and what we can and cannot use the data for.
The dataset is periodically updated. From time to time, I intend to incorporate these updates. This fork contains the version of Ogan’s data that I am using. If updates there require updates to this article, I will add them at the same time.
Provenance
At the time of writing, the dataset contains 9890 characters collected between 2018/04/06 and 2021/08/14 using Ogan’s PDF exporter and character sheet. It is available under an MIT license. In their own discussion, Ogan explains that they created the dataset as an open alternative to a closed dataset created by D&D Beyond and used here. The dataset has been produced without an agenda, and made available without strings. This means we can be optimistic that the data is not concealing anything, and are free to follow it to the conclusions it leads to, whatever they may be.
Limitations
The dataset has some limitations we must address. These are Dragons we will kill later.
Invalid Characters and Fields
The apps provide several free text fields. Thankfully, Ogan has provided processed versions of these. Alignment is matched against individually specified strings. Weapons are matched to the official weapon lists, with some heuristics and manual labeling. Spells are hard, but Ogan’s solution is sufficiently thorough. Invalid fields are left blank. Ogan’s justification of data cleaning is satisfactory for me, so we will used the processed fields. Thanks!
It is also possible that some characters are not real, and that some are duplicates. We will address this later by trying to identify and remove these entries. Ogan also offers a solution — I will use this as validation of my method. This is tricky to get right, but hopefully we will both come to more or less the same conclusion.
Selection Bias
Ogan’s apps were advertised on r/dndnext and r/dnd. While they are publicly available, it is likely their users will predominantly hail from the subreddits. This creates a potential for a selection bias: rather than reflecting the general population of D&D players, the data shows the behavior of members of the subreddits.
The question is therefore whether these groups are representative of D&D players in general. In Ogan’s article, this dataset is contrasted with that in the fivethirtyeight article. Where comparisons are possible, they generally correlate, suggesting that it is a fair representation of the wider group.
At the very least, this dataset will represent the behavior of members of these communities. This is sufficient for us to draw conclusions about how a group of people who are “in the know” about D&D play. We can also be reasonably confident that the conclusions should a fairly accurate representation of the global D&D community, particularly if our findings continue to match what other articles say.
Dragons
Having identified the dataset’s weaknesses, it is time to address them.
Sanity Checks
We can use some quick checks to remove impossible characters. All characters should have a level between 1 and 20, and HP between 1 and 400. Even with magic items, ability scores are limited to 3-30.
Extra Content
D&D has lots of extra content. Rather than doing an exhaustive study of all characters, we are going to focus on core content. Remember, our plan is to produce general conclusions — we can expect homebrew and non-core content to follow the same trends. Core content forms the vast majority of the dataset (there are 136 Artificers compared with 594 Monks, for example), so will be less impeded by outlier classes. We can also remove experimental Unearthed Arcana, which may have an unanticipated effect.
I have removed all entries that use a race or class not in the PHB. I have also removed multiclass characters with more than three classes — these tend to be experimental characters, such as one with a level in every class.
Non-Unique Characters
Ogan identifies 7110 unique characters by filtering characters with the same name and class, and keeping entry with the higher level.
I am going to label the unique subset of data, but will keep some non-unique values. For some analysis, the unique set is better (what race is most popular?), but for others the full set is better (at what level do most people play?). As such, I will not remove entries for the same character at multiple levels. However, I will remove characters with the same name and level, as these duplicates will not offer new data. In these cases, I will keep the most recent addition.
I have intentionally performed this filtering after the other checks. In cases of non-unique characters, the first move is to remove any invalid characters. This ensures we keep as many valid characters as possible.
Irrelevant Fields
Our goal is to examine how people play D&D mechanically. This is not a demographic survey, so several fields are of no interest to us. ip, finger, date, country, and countryCode are all metadata about collection. They will not inform us about mechanics in general, so we can ignore them.
As we are using the processed versions of some fields, we can also remove weapons, alignment, and spells. I will also remove good and lawful, which are unused. The processed version of race looks reasonable, so we can drop that as well. name is not relevant to mechanics, and is a hash value anyway, so we can now discard it along with hash, which is undocumented. We must keep class to multiclass level breakdowns, but will also keep justClass for ease. levelGroup is encapsulated in level, so we can safely keep just the later.
The Final Dataset
The final dataset contains 5848 rows, and the following fields: background, class*, justClass*, subclass*, level, feats*, HP, AC, Str, Dex, Con, Wis, Wis, Int, Cha, skills*, castingStat, choices**, processedAlignment, processedRace, processedSpells*, processedWeapons*, and duplicated.
duplicated is a boolean value that is true only for non-initial, non-unique values. By selecting only rows where it is false, we get a dataset of unique characters. Fields marked * contain lists of values separated by |. We can break those down further when we need them. choices gets special attention, as it is more complex. When we need to parse it, we will need to be careful. Spells are separated by | and in the format SPELL*LEVEL.
Breakdowns
We now have a dataset, and can start looking at it’s shape.
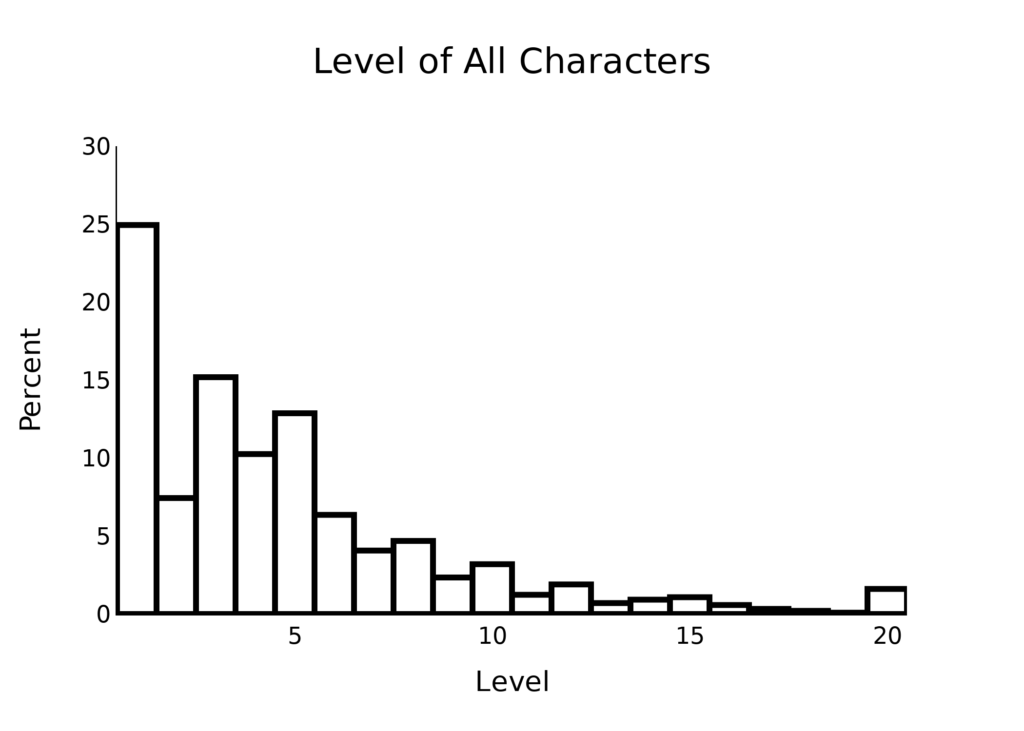
First, we can break down level. This histogram shows both unique and non-unique characters, so we can see that even in longer campaigns characters rarely reach higher levels. The spikes at levels 1 and 20 are almost certainly for one-shots. Typical games appear to start at level 3, where most subclasses come online. I would guess experienced groups then pick levels where interesting features appear for oneshots (5, 10, and 12).
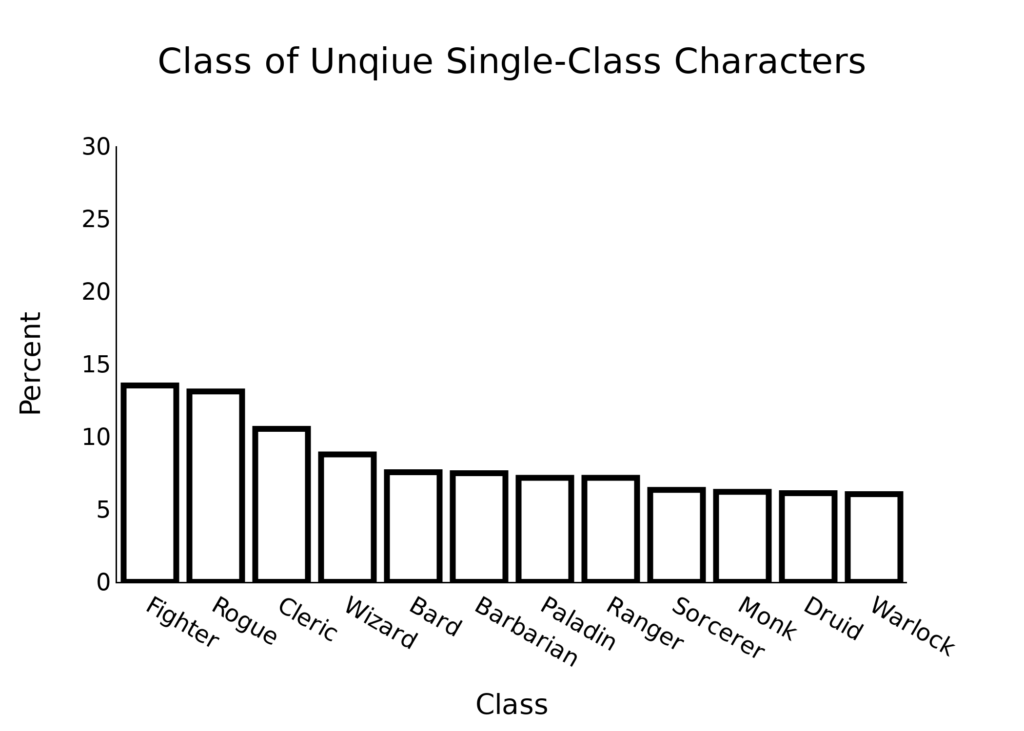
We have a good spread of classes. This figure excludes non-unique characters and multiclassing characters. It is unsurprising that the “classic” classes of Fighter, Rogue, Cleric, and Wizard are the most popular.
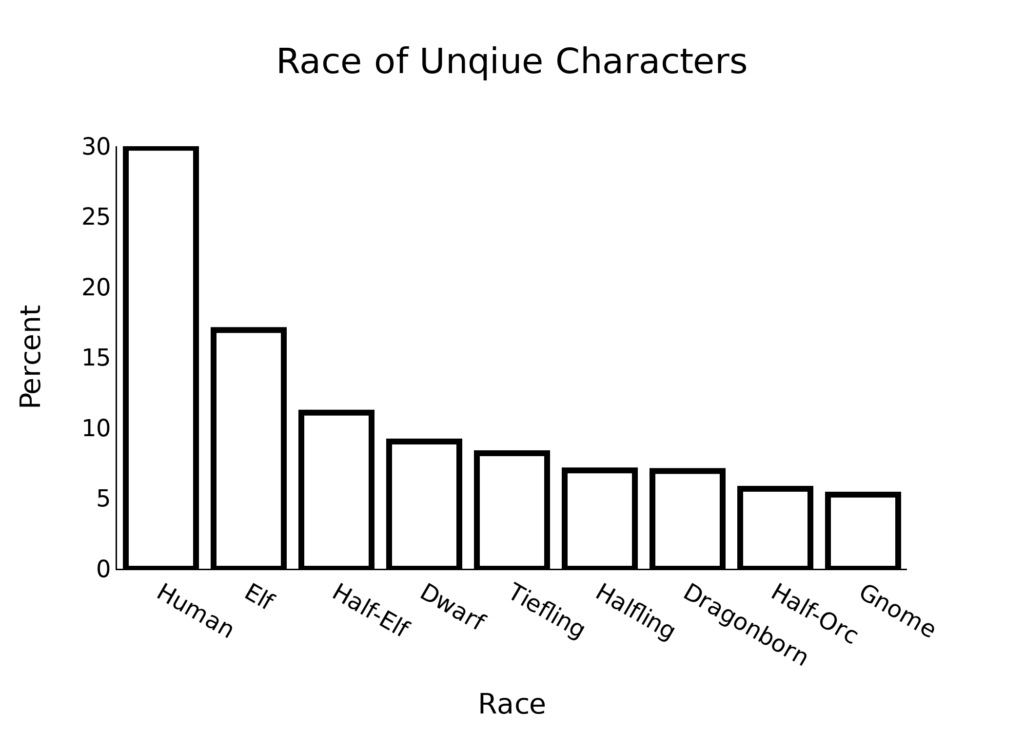
Race is less even. We will need to dig a bit deeper to find out why, but it appears the flexibility of Humans (for either ability scores or a feat) wins them points. With a bonus to Dexterity, Elves are a reasonable choice for may builds, and offer subraces that lean in several directions, providing similar flexibility. Gnomes, on the other hand, have a boost to Intelligence (really only needed by Wizards), Superior Darkvision (which is hard to use), can hide in rocks (which is hard to use, and not what Wizards want to do anyway), and a few other minor abilities that are…hard to use effectively.
Firm Foundations
At the ends of all that, we have our data set. In future, we shouldn’t need to be quite so thorough — we can trust that our work today was enough to ensure the dataset is as correct as possible. If you want to check my working, it is available here. Feel free to use it for your own analysis, and see if we reach the same conclusions.
Hey,
Thanks for this, really interesting analysis. However, I do have one query – this article seems to suggest that it is inherently better for players to select class and race in an even distribution, however I would question that assumption, particularly given that I doubt players behave as fully rational actors during character selection. What is the justification for trying to attain an even distribution?
A reasonable challenge. If players choose at random, we should expect a uniform distribution. If all options are balanced, players who min-max should also produce a uniform distribution. If min-maxers instead have a preference for one option, we can use it as evidence that the options are not balanced, which is problematic for players choosing at random — they are at risk of shooting themselves in the foot, and the game punishes their lack of rational decision making. That’s why I think a uniform distribution is desirable — it shows balance was done right.
Unfortunately (for my analysis), some players will choose options based on the story they want to tell, which introduces uncertainty. I would hope that every option had roughly the same “story appeal” so that there are no dead end options that the developers spend time working on only for them to be ignored — this would also produce a uniform distribution. However, I suspect this will be driven by what people see in other fantasy stories, so will be at least partially responsible for the Human spike.